AlexNet
首次在CNN中成功应用了ReLU、Dropout和LRN等Trick,同时也使用了GPU进行运算加速。
五个卷积层、三个Max Pool和三个全连接。每个卷积层使用ReLU激活。有8层需要训练的卷积层。
成功应用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。
训练时在后几层全连接层使用Dropout随机忽略一部分神经元,以避免过拟合。
在CNN中使用重叠的最大池化。
提出了LRN层,临近抑制,对局部输入区域进行归一化。
使用CUDA加速深度卷积网络的训练,利用GPU处理大量的矩阵运算。
数据增强,随机地从原始图像截取。可以大大减轻过拟合,提升泛化能力。

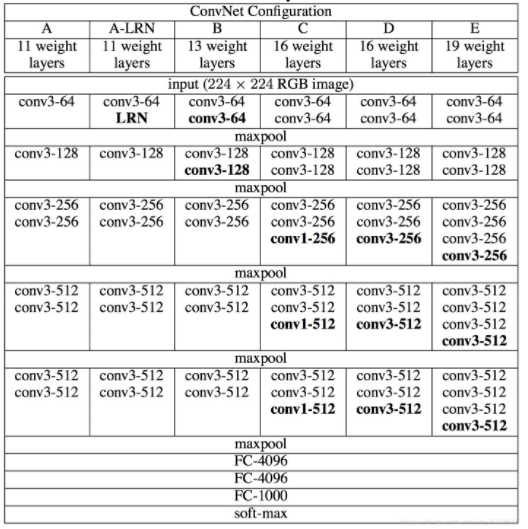
VGGNet
VGGNet探索卷积神经网络的深度与其性能之间的关系,通过反复堆叠3×3的小型卷积核和2×2的最大池化层,成功地构建了16-19层深的卷积神经网络。
全部使用3×3的卷积核和2×2的池化核,通过不断加深网络结构来提升性能。
拥有五个卷积模块和一个三层的全连接分类网络,每个卷积模块有2-3个卷积层,后面有一个最大池化层来缩小图片的尺寸。
训练时在后几层全连接层使用Dropout随机忽略一部分神经元,以避免过拟合。
得到的结论:LRN层作用不大、越深网络效果越好、3×3的卷积核效果较好。
由于网络很深,所以训练的时候先训练A这种简单的网络,再服用A网络的权值初始化后面几个复杂的网络,这样收敛速度快。
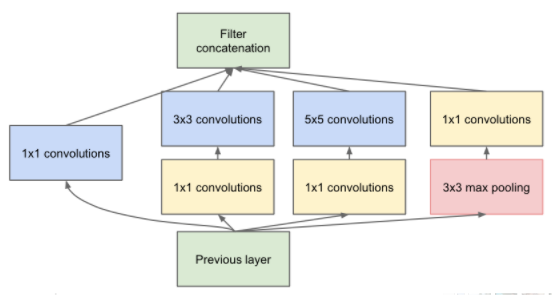
Google Inception Net
V1
降低参数量的目的:参数越多模型越庞大,需要的数据也就越多,而高质量的数据非常昂贵。参数越多,耗费的训练资源也就越大。
参数少但效果好的原因:模型更深、表达能力更强;去除了最后的全连接层,用全局平均池化层来取代;精心设计的Inception模块提高了参数的利用效率。
去除全连接层:全连接层几乎占据了AlexNet和VGGNet中90%的参数量,而且会引其过拟合,去除全连接层后模型的训练速度更快并且减轻了过拟合。
1×1的卷积:增加一层特征变换和非线性,能够跨通道组织信息,提高网络中的表达能力,可以对输出通道升维或者降维。
Inception模块:四个分支,使用不同尺寸的1×1、3×3、5×5等卷积核。
辅助分类节点:将中间某一层的输出用作分类,并按一个较小的权重加到最终的分类结果中。相当于做了模型融合,同时增加了反向传播的梯度信号,也提供了额外的正则化。
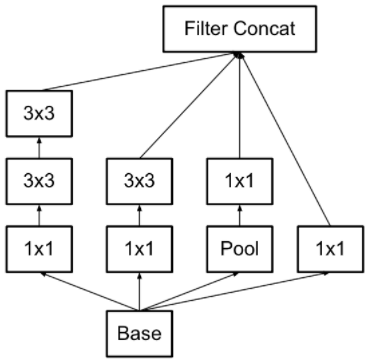
V2
学习了VGGNet,使用两个3×3的卷积代替5×5的大卷积核:不仅可以减低参数量减轻过拟合,还可增加非线性增加特征变化。
提出了Batch Normalization(BN):非常有效的正则化方法。可以减少或者取消Dropout,简化网络结构。
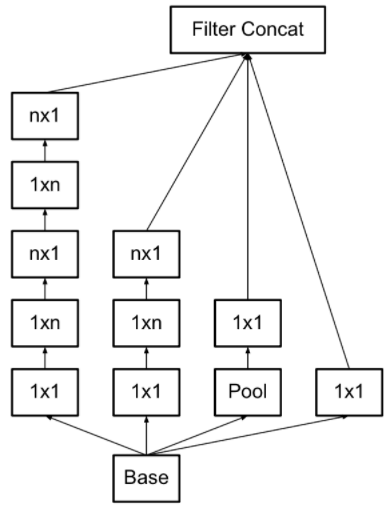
V3
将一个较大的二维卷积拆成两个较小的一维卷积,比如将7×7的卷积拆成1×7卷积和7×1卷积,或者将3×3的卷积拆成1×3卷积和3×1卷积。
拆分可以节约大量参数、加速运算并减轻过拟合,同时增加了一层非线性,扩展模型表达能力。
优化了Inception模块的结构,比如在模块的分支中又出现分支。
V4
- V3结合了ResNet。
Feature Extractor - Inception v4
可借鉴的Trick
有待补充
ResNet
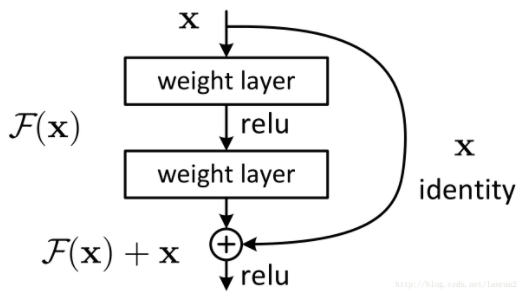
假定某段神经网络的输入是
x,期望输出是H(x)。如果直接把输入x传到输出作为初始结果,那么此时我们需要学习的目标是F(x)=H(x)-x。
残差学习单元相当于把学习目标改变了,不再是学习一个完整的输出
H(x),而是学习输出和输入的差别H(x)-x,即残差。Shortcut或Skip Connections:ResNet和其他模型的区别是有很多旁路的直线将输入直接连接到后面的层,使得后面的层可以直接学习残差。
不使用Res模块的网络通常会存在信息丢失的问题,Res模块在一定程度上解决了这个问题,保护了信息的完整性。
ResNet只学习输入和输出的差别,这样就简化了目标和难度。
残差学习模块的思想具有很强的推广性。
V2
- 用Identity Mappings(y=x)代替非线性激活函数。
发展方向
网络结构上的改进调整
网络深度的增加
