垃圾回收
Python采用的是“引用计数”为主,“标记-清除”和“分代收集”为辅的策略。
在Python中,如果一个对象的引用数为0,Python虚拟机就会回收这个对象的内存。“引用计数”的缺陷是“循环引用”的问题。
“标记-清除”就是让被“循环引用”的无用对象的引用数为0,从而让Python虚拟机回收这个对象的内存。
“分代收集”是一种典型的“以空间换时间”的技术。简单来说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集。
GC系统
三个主要任务:
- 为新生成的对象分配内存
- 识别那些垃圾对象,并且
- 从垃圾对象那回收内存
引用计数
python里的每一个东西都是对象,核心是“PyObject结构体”:
1 | typedef struct_object { |
“PyObject”是每个对象必有的内容,其中“ob_refcnt”就是做为“引用计数”。
当一个对象有新的引用时,它的“ob_refcnt”就会“增加”;当引用它的对象被删除,它的“ob_refcnt”就会“减少”。
1 | #define Py_INCREF(op) ((op)->ob_refcnt++) //增加计数 |
当引用计数减少为0时,Python立即将其释放,把内存还给操作系统,该对象生命就结束了。
导致引用数+1的情况
- 对象被创建,如
a=1 - 对象被引用,如
b=a - 对象被作为参数传入到一个函数中,如
func(a) - 对象作为一个元素存储在容器中,如
list1=[a, b]
导致引用数-1的情况
- 对象的别名被显式销毁,如
del a - 对象的别名被赋予新的对象,如
a=2 - 一个对象离开作用域,例如
函数执行完毕时函数中的局部变量、传入的参数 - 对象所在的容器被销毁或从容器中删除
引用计数的优点
- 简单易理解
- 实时性:一旦没有引用,内存就直接释放了。处理回收内存的时间分摊到了平时。
引用计数的缺点
- 维护引用计数消耗资源:每个对象中都要引用数。
- 不能处理“循环引用”:list1与list2相互引用,如果不存在其他对象对它们的引用,list1与list2的引用计数也仍然为1,所占用的内存永远无法被回收。
1
2
3
4list1 = []
list2 = []
list1.append(list2)
list2.append(list1)
标记-清除
“标记-清除”机制:首先标记对象(垃圾检测),然后清除垃圾(垃圾回收)。
“标记-清除”是为了解决循环引用的问题。可以包含其他对象引用的容器对象(比如:list,set,dict,class,instance)都可能产生循环引用。
“标记-清除”将集合中对象的引用计数复制一份副本,改动该对象引用的副本。对于副本做任何的改动都不会改动真实的引用计数,因此不会影响对象生命周期的维护。
这个“计数副本”的唯一作用是寻找root object集合(该集合中的对象是不能被回收的)。
当成功寻找到root object集合之后,首先将现在的内存链表一分为二,一条链表中维护root object集合,成为root链表,而另外一条链表中维护剩下的对象,成为unreachable链表。
分成两个链表是因为:现在的unreachable可能存在被root链表中的对象直接或间接引用的对象,这些对象是不能被回收的,一旦在标记的过程中,发现这样的对象,就将其从unreachable链表中移到root链表中;当完成标记后,unreachable链表中剩下的所有对象就是垃圾对象了,接下来的垃圾回收只需在unreachable链表中执行即可。
分代收集
一定比例的内存块的生存周期都比较短,通常是几百万条机器指令的时间;而剩下的内存块,起生存周期比较长,甚至会从程序开始一直持续到程序结束。
“分代收集”是一种典型的“以空间换时间”的技术。简单来说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集。
“分代收集”就是将回收对象分成数个代,每个代就是一个链表(集合),代进行“标记-清除”的时间与代内“对象存活时间”成正比例关系。
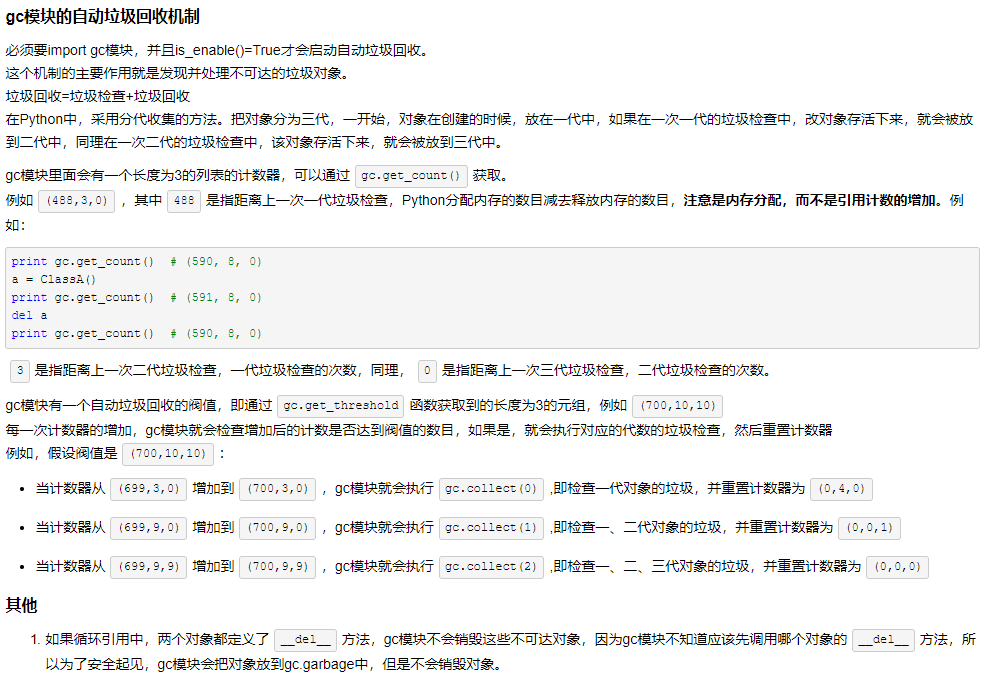
“分代收集”把对象分为三代,一开始在创建对象的时候放在一代中。如果在一次一代的垃圾检查中,改对象存活下来,就会被放到二代中,同理在一次二代的垃圾检查中,该对象存活下来,就会被放到三代中。
python里一共有三代,每个代的threshold值表示该代最多容纳对象的个数。默认情况下,当0代超过700,或1,2代超过10,垃圾回收机制将触发。
0代触发将清理所有的三代,1代触发会清理1,2代,2代触发后只会清理自己。