图像的语义分割
欢饮达旦,大醉,作此篇,兼怀Offer。
这几天面试,给面试官讲语义分割,面试官好像都不是很懂似的(希望不是我搞错了吧☯)。几乎上每次都得先探讨一下什么是语义分割。
总结
需要掌握以下方面:
- 掌握一个过程:从粗略到精细的过程。
- 掌握三种改进方向:卷积模块的设计(Inception、Res模块、Xception)、编解码的设计、上下文信息的整合(多尺度聚合、特征融合、空洞卷积级联、金字塔池化模块)。
- 掌握三种架构/结构/模块:编码解码架构、空洞卷积结构、金字塔池化模块。
- 掌握三个架构图:FCN、PSPNet、DeepLab。
基本概念
图像语义分割可以说是图像理解的基础技术,在自动驾驶系统(街景识别与理解)、无人机(着陆点判断)以及穿戴设备中举足轻重。
图像由许多像素组成,而“语义分割”就是将像素按照图像中表达“语义”含义的不同进行“分割”(Segmentation)。
街景识别示例:

实例分割示例:
前DL时代的语义分割
DL之前的语义分割工作多是根据图像“像素自身的低阶视觉信息”来进行图像分割。这样的算法复杂性不高,在较困难的分割任务上的分割效果不好。
常见算法:
- 像素级别的“阈值”分割法
- 基于“像素聚类”的分割方法
- 基于“图划分”的分割方法
DL时代的语义分割
在计算机视觉进入深度学习时代之后,语义分割进入了全新的发展阶段。
以全卷积神经网络(Fully convolutional networks,FCN)为代表的一系列基于卷积神经网络的语义分割方法相继提出,屡屡刷新图像语义分割的精度。
深度学习早期
“图像块”分类:利用像素周围的图像块对每一个像素进行分类。
缺点:因为卷积分类网络有全连接层,所以输入图片需要有固定的大小。
全卷积神经网络(FCN)
“全卷积神经网络”可以说是深度学习在“图像语义分割”任务上的开创性工作。
端到端的卷积网络
“FCN”直接进行“像素级”“端到端”的“语义分割”。基于主流的深度卷积神经网络模型来实现,主要是修改ImageNet预训练模型。
卷积成替换全连接层
一般来说,对ImageNet进行分类的卷积分类网络的后三层是全连接。
在FCN中,将含有全连接的卷积网络的前两个全连接层替换为两个卷积层,将最后一个全连接层替换为有21个1×1卷积核的卷积层。
但是,由于pool的下采样,使得最后的特征图大小比原图小,这就给训练带来了问题。为了解决下采样的问题,FCN利用双线性插值将网络的特征图上采样到原图大小。
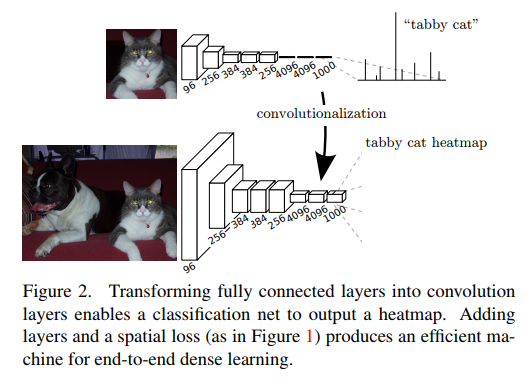
引入跳跃连接改善上采样的粒度
另外,为了更好地预测图像中的细节部分,FCN还将网络的pool4和pool3的浅层特征图也考虑近来,分别作为FCN-16s和FCN-8s的输出,与原来FCN-32s的输出结合在一起做最终的语义分割结果。
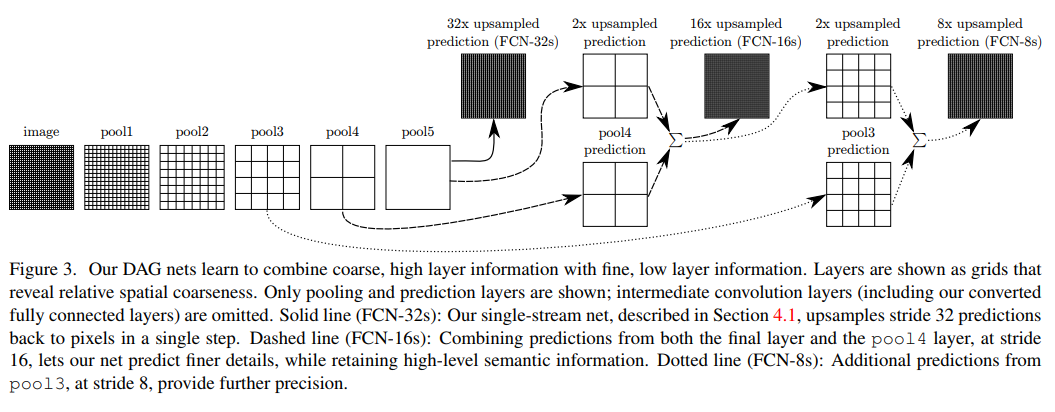
由于池化操作造成了信息损失,上采样只能生成粗略的分割结果,所以从高分辨率的特征图中引入“跳跃连接”改善上采样的精度。
结果比较
从结果中可以看出,由于池化层的下采样倍数的不同导致不同的语义分割精细程度。FCN-32s利用了最后一层池化的输出,下采样倍数较高,对应的语义分割结果最为粗略。FCN-8s因下采样倍数较小可以取得较为精细的分割结果。

任意图像大小
由于没有全连接,所以可以对“任意大小的图像”进行“语义分割”,且比“图像块”方法快很多。
SegNet
FCN网络中使用了“解卷积层”(或双线性插值)和“少量的跳跃连接”,因此,输出的分割结果比较粗糙。
SegNet引入了更多的“跳跃连接”。
SegNet没有使用FCN中“编码器”产生的特征图,而是使用了“最大池化层的索引”。

Dilated Convolutions
通过空洞卷积进行多尺度上下文聚合。
FCN的问题
由于池化层的存在,特征图的大小越来越小。FCN的设计初衷是需要和输入大小一致的输出,因此FCN做了上采样。但是上采样并不能将丢失的信息全部无损地找回来。
去掉池化层
Dilated Convolution是一种很好的解决方案:既然池化的下采样操作会带来信息损失,那么就把池化层去掉。
但是池化层去掉随之带来的是网络各层的感受野(Receptive field)变小,这样会降低整个模型的预测精度。
Dilated Convolution的主要贡献是,如何在去掉池化下采样操作的同时,而不降低网络的感受野。
卷积对比
众所周知,“图像语义分割”需要获取“上下文信息”帮助提高准确率。
不使用空洞卷积的传统卷积通过“下采样(pooling)”来增大感受野,以此获取上下文信息。
- 卷积核的大小不变
- 减少了数据量
- 有利于防止过拟合
- 但是损失了分辨率,丢失了一些信息
空洞卷积通过膨胀卷积核来增大感受野,以此获取上下文信息。
- 参数个数没有增加
- 数据量没有减少
- 分辨率没有损失(膨胀卷积支持以指数级扩增感受野且没有分辨率损失或者覆盖)
- 但是计算量增大,内存消耗增大
空洞卷积感受野计算
从传统卷积的定义到膨胀卷积的定义:传统卷积是膨胀卷积的特例
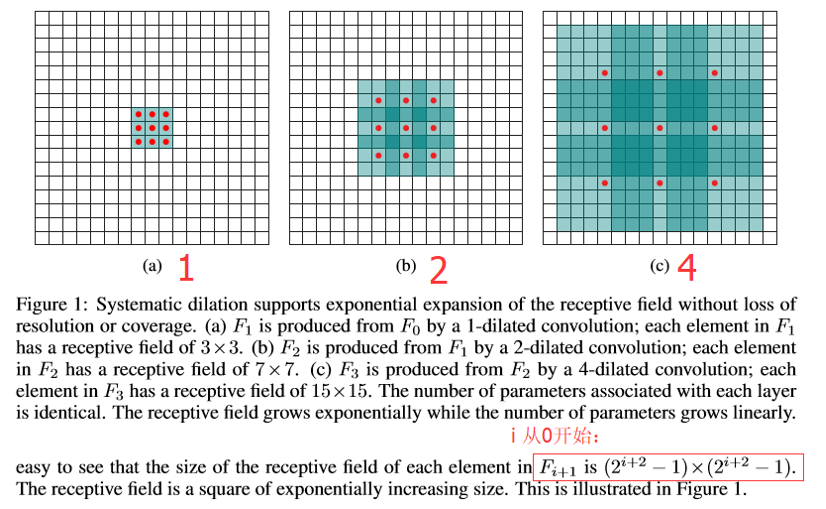
多尺度上下文信息聚集
使用膨胀卷积收集多尺度上下文信息且没有分辨率损失。
待补充。
PSPNet
主要贡献
- 使用“空洞卷积”来改善“ResNet”
- 提出“金字塔池化模块”帮助聚合上下文信息
- 用了辅助损失(auxiliary loss,在主分支损失之外增加了辅助损失)
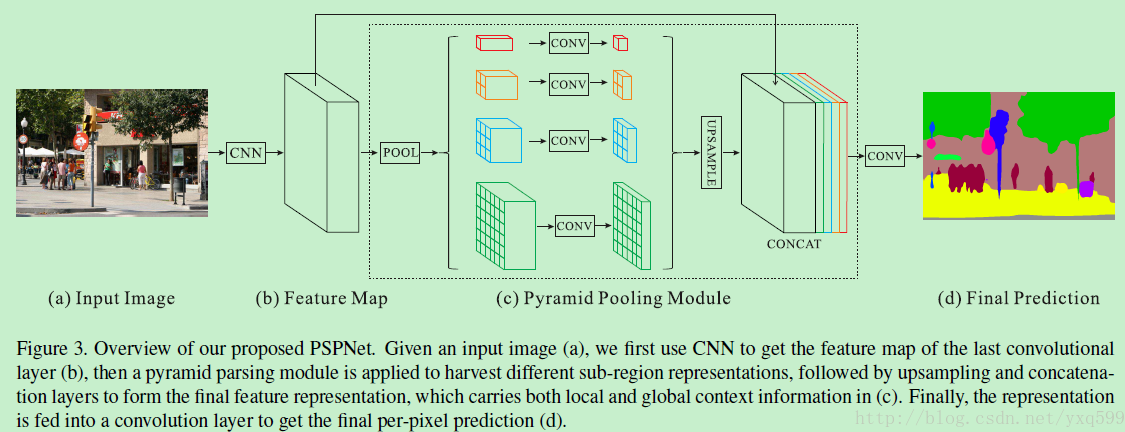
金字塔池化模块
金字塔池化模块通过“较大核的池化层”获取“全局的场景分类”信息,提供语义分割的“类别分布信息”。
金字塔池化模块连接“ResNet的特征图”和“并行池化层的上采样结果”。
信息全在图上了:
DeepLab 系列
有待补充
- 使用“带孔/空洞”卷积改进ResNet模型:在不增加参数的情况下扩大感受野。
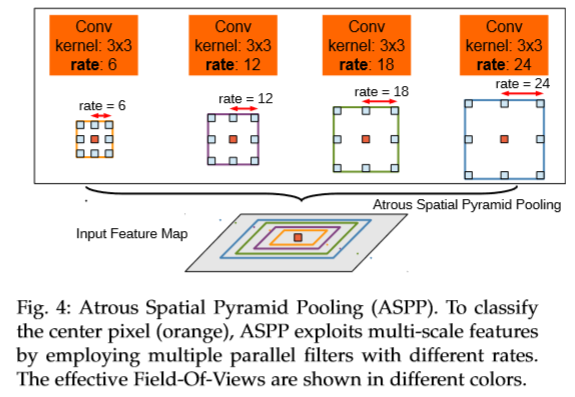
- 提出了“空洞金字塔模块”(ASPP模块):通过不同的rate产生一组特征图,从而捕获多个尺度的对象。
- 采用了全连接CRF(条件随机场)
- 在编码过程中获取上下文信息,因此不需要很大的解码网络。
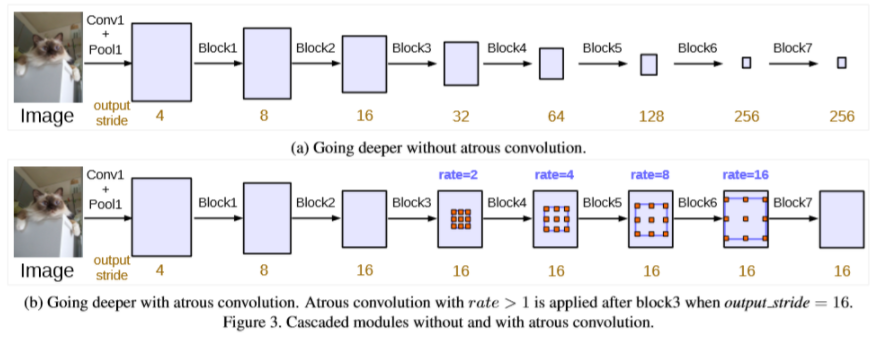
- V3:级联或者并行地应用atrous卷积模块。
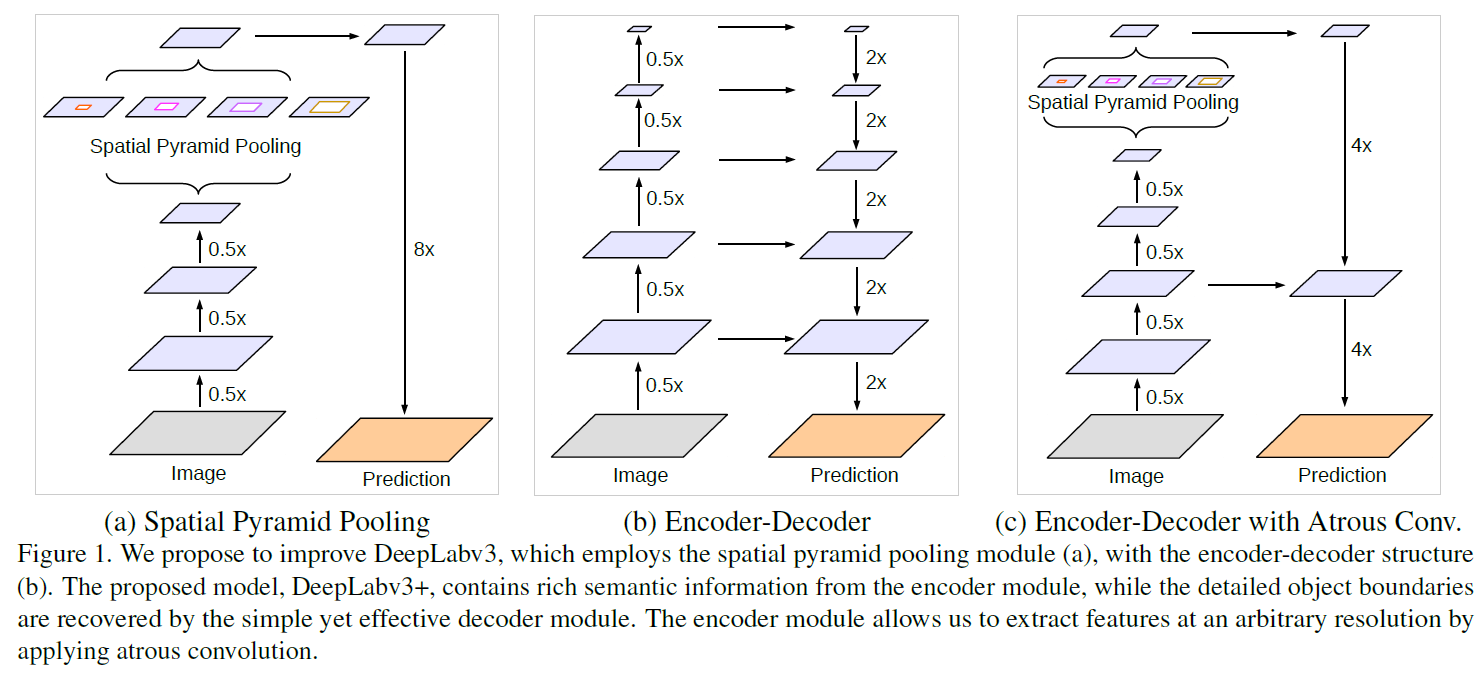
- V3++:以DeepLabv3作为encoder模块,并添加了一个简单却有效的decoder模块。
- V3++:将Xception应用于分割任务中。
V2的ASPP模块:
级联地应用atrous卷积模块:
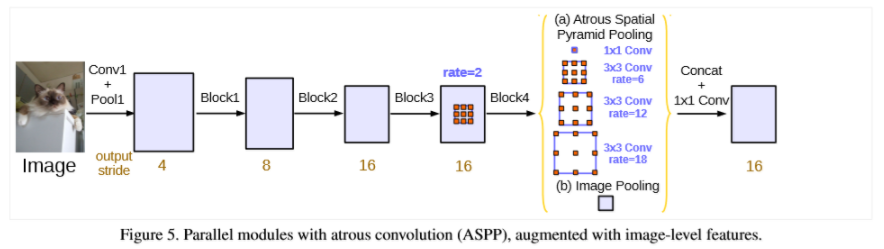
并行地应用atrous卷积模块(ASPP):
V3++结合encoder-decoder架构:
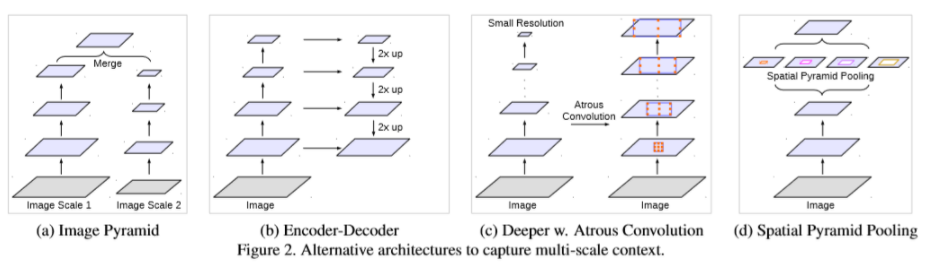
捕获上下文信息的四种方式:
RefineNet
有待补充
后处理
条件随机场
通常CRF被用于后处理以改进分割结果(表示怀疑)。
CRFs是一种基于“底层图像的像素强度”进行“平滑分割”的“图模型”。相似强度的像素趋向于标记为同一类别。
发展
从粗略到精细的过程
图像的语义分割是一个从粗略到精细的过程。
图像分类 => 目标检测 => 语义分割 => 实例分割 => 关键点检测

三种改进方向
卷积模块
设计更有效的卷积模块,更好地提取特征。
- 反卷积
- Inception
- Xception
- Res模块
- 空洞卷积
解码变种
设计更好的编码器和解码器,逐渐的获得清晰的物体边界。
- 解码器和编码器的设计
整合上下文信息
整合不同空间尺度的上下文信息,对局部信息和全局信息进行平衡。
捕获上下文信息的四种方式:
- 多尺度聚合:将图像resize到多个尺度分别分割,最后整合分割结果。
- 特征融合:提取不同层的特征进行融合,包含了不同的局部上下文信息。例如跳跃连接。
- 膨胀卷积:膨胀卷积核获得更大的感受野(带孔卷积)。例如PSPNet和DeepLab。
- 金字塔池化:例如PSPNet和DeepLab
三种架构/结构/模块
Encoder-Decoder架构
“编码器”通过“池化层”逐渐“减少空间维度”,“解码器”逐渐“恢复物体的细节和空间维度”。
为了使“解码器”有更好的物体细节,通常会有“从编码器到解码器的shortcut连接”。
代表模型:
- U-Net
- SegNet/DeconvNet
- RefineNet
Dilated/Atrous convolutions结构
使用“空洞”/“带孔”卷积代替“池化层”。
代表模型:
- PSPNet
- DeepLab V1/V2/V3
金字塔池化模块
整合特征图的上下文信息。
代表模型:
- ASPP:DeepLab中的空间空洞金字塔池化模块。
- PPM:PSPNet中的金字塔池化模块。
