遥感图像的地物分类
介绍项目
这个项目是去年参加的一个比赛,是对遥感图像进行地物分类。
遥感图像类似于百度地图中的卫星图像,是在卫星或者飞机上拍摄的,分辨率比较低,一个像素大概代表半米左右。
地物分类是地面上的物体进行分类,这个比赛将整个图像分成:水、植被、道路和建筑。
对整个图像分类也就是像素级分类,也可以理解成语义分割,类似于自动驾驶中对道路、行人等进行分割。
比赛难点/解决方案
遥感图像的分辨率较低
一般来说,自然图像的分辨率较高,图片上的物体较大,而遥感图像的分辨率较低,图片上的物体较小,比如说建筑。
如果按照滑窗来对一张图片进行分类的话,一张图片上可能包含多个类别,对最终的结果会产生影响。
所以,使用了当前比较流行的全卷积网络,进行地物分类。
样本类别不均衡
观察数据发现类别间不均衡,比如水和道路较少。所以需要对类别少的类别进行增强。
解决办法:
采用两个步骤的数据增强。
因为发布数据的大小是5000×5000左右的,需要裁剪出300×300左右的图片然后再送入到全卷积网络中。
在网络开始训练之前,搜索裁剪出来的数据,找到含水或者道路比较多的图片,通过旋转等方式增加这类样本的数量。
在网络训练时,再通过上下左右翻转、色彩变换等方式进行进一步的数据增强。
PSPNet
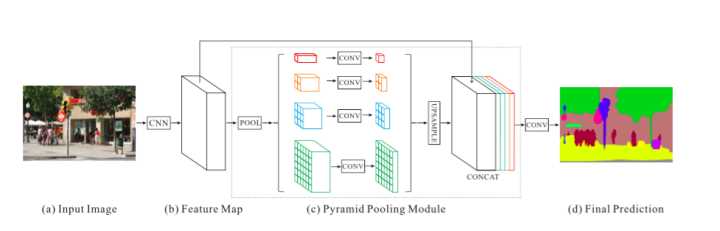
网络分为三部分,第一部分是用CNN网络进行特征提取,第二部分是金字塔池化模块,用来聚合上下文信息,第三个部分是对金字塔模块得到的特征图进行卷积得到最终的预测结果。
有两部分损失,一部分是标签和预测softmax之间的交叉熵,一部分是用来正则化的辅助损失。
创新
结果融合:不同的输入大小、图像镜像翻转(Boosting,按照总损失计算不同模型的权重)
输入图像采用不同的大小,然后将得到的结果进行融合。(5种不同的输入,比如投票法)
对图像进行上下左右的翻转,然后进行融合。(对logits/softmax进行融合)
修改金字塔池化模块,保留图像细节
原始的PSPNet是针对PASCAL VOC 2012等数据集的网络架构,这些数据集都是自然图像,和遥感图像相比,物体一般比较大,所以1×1、2×2、3×3和6×6的金字塔池化模块比较有效。
而比赛中的数据是遥感图像,建筑、道路等物体都比较小,所以将原始的金字塔池化模块中的1×1修改为8×8。虽然效果提升的不高,但还是有的。
结合DeepLab中的ASPP,更好的聚集上下文信息
金字塔池化模块采用全局平均池化,丢失了大量的信息,保留了全局上下文信息,虽然对区域一致性有帮助,但丢失了细节信息。
而DeepLab中的ASPP采用空洞卷积,通过不同的空洞率产生一组特征图,从而捕获多个尺度的对象。这样没有丢失信息,但是增加了感受野,在一定程度上也得到了全局上下文信息。
在网络中同时使用两个模块,将特征图进行拼接后载进行下一步操作得到最终结果。
现在有一个趋势是将比较成功的CNN进行模块化,称为神经网络的一个组件,从而组成相对复杂的网络。
对最终结果进行去噪
。。。
卫星影像的AI分类与识别
比赛地址:卫星影像的AI分类与识别
题目:基于深度学习的遥感影像地表覆盖、地表利用分类
简单来说就是“地物像素级分类”。
数据
本次比赛提供的样本是2015年中国南方某地区的高分辨率遥感影像,空间分辨率为亚米级(每个像元表示的范围在1米内),光谱为可见光波段(R,G,B)。
提供两张训练图片和标签,三张测试图片,每张大小为5000*5000左右。
样本为五类:植被(标记1)、建筑(标记2)、水体(标记3)、道路(标记4)以及其他(标记0)。
其中,耕地、林地、草地均归为植被类。影像收集的时间跨度从4月到8月,地表的变化较大。部分耕地和林地处于收获或砍伐后的状态,均被划为植被类。
部分图片及标签:
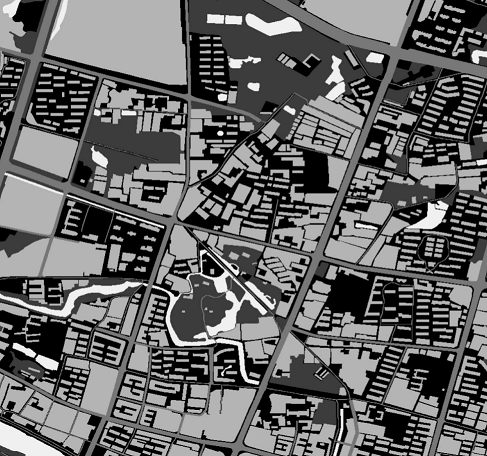
任务描述
通过算法或模型,对该地区2015年数据的地表覆盖物准确地进行分类。
评估标准:分类结果以准确率(overall accuracy)作为主要评估标准。
其他类(标记为0)的分类精度不算入最后精度评判标准,最后结果只统计植被、道路、建筑、水体四类的分类精度。
数据分析
数据为5000×5000的大图,训练图片的标签是像素级。
数据主要存在以下几个问题:
异构数据,类内差别较大(颜色增强)
除了水体,另外三个类都属于异构数据,类内差别较大。
以植被类为例:比如耕地、林地、草地都是植被;影像收集的时间跨度从4月到8月,地表的变化较大;部分耕地和林地处于收获或砍伐后的状态,均被划为植被类。
训练图片和测试图片的分布不一致
训练图片偏向城市,测试图片偏向郊区和乡下。这就导致训练和测试的植被风格、建筑风格、道路风格都不一致。
各类别数据量不平衡(对图片进行重采样,类别少的地方进行小步长滑窗)
训练图片中城区类型的建筑物比较多,植被和水体比较少,而测试图片中乡村类型的建筑物比较多,植被和水体较多。
部分训练图片:
部分测试图片:
模型选择
传统的机器学习模型,比如说SVM,没有深度卷积神经网络的效果好,所以不考虑使用非深度学习的模型。
根据先前的经验,适合该比赛的深度学习模型有两种方式:按Patch滑窗的卷积网络和End-to-End的全卷积网络。
- 按Patch滑窗的卷积网络:由于是密集分类,待分类的像素比较多,所以分类速度比较慢,易产生大量的噪点,但是边界较准确。
- End-to-End的全卷积网络:由于不需要进行滑窗且是端到端网络,所以分类速度较快,且效果较好,但是边界不准确。
由于我们是两个人参加的比赛,所以选择了这两种方案并在后期进行模型融合。
按Patch滑窗的卷积网络使用“GoogLeNet”网络作为分类器,End-to-End的全卷积网络使用“PSPNet”架构。
按Patch滑窗的卷积网络 - GoogLeNet
主要思路:该方法是在测试和训练图片上进行滑窗采样获得大小为N×N的样本,然后使用Inception网络对N×N的样本进行分类。
在2014年ILSVRC挑战赛中,GoogLeNet获得冠军,可见其分类性能较好。GoogLeNet计算效率明显高于VGG,模型参数较少。
Inception从V1到V4有很多改进,包括使用Inception模块、加入BN层、卷积分解、加入残差思想等,这些改进都使得Inception分类性能更好、计算效率更高、模型参数更少。
但是ImageNet比赛的数据量非常庞大,且类别数较多。而本次比赛的数据类别较少,直接使用GoogLeNet达不到预定的效果。因此需要将GoogLeNet网络加以修改来适应本次比赛的数据。
End-to-End的全卷积网络 - PSPNet
主要思路:将大图切分成N×N的图,然后送入到PSPNet中直接得到最终分类结果。
PSPNet使用了“空洞卷积”来改善ResNet,增加了“金字塔池化模块”帮助聚合上下文信息。另外采用了主分支之外增加了辅助损失。
PSPNet在PASCAL VOC 2012测试集上达到了85.4%的mIoU。
PSPNet网络架构:
数据预处理/数据增强
将数据处理成tfrecord的格式。
对数据进行左右翻转、剪切、色彩增强等。(自然图像一般左右翻转,遥感图像没有方向性,所以可以进行360度的旋转)
各种增强方式
End-to-End的全卷积网络 - 模型改进
创新很难,不知道下面的算不算创新,也许只算改进。
将PPM(金字塔池化)模块和ASPP(空间空洞金字塔池化)模块结合,同时使用两个模块并拼接两个模块的输出。
原始的PSPNet是针对PASCAL VOC 2012等数据集的网络架构,这些数据集都是自然图像,物体一般比较大,所以1×1、2×2、3×3和6×6的金字塔池化模块比较有效。
而比赛中的数据是遥感图像,建筑、道路等物体都比较小,所以将原始的金字塔池化模块修改为2×2、3×3、6×6和8×8的金字塔模块。虽然效果提升的不高,但还是有的。原始的PSPNet处理的类别较多,所以使用了ResNet50进行特征提取。在训练过程中发现,训练到一定的代数就会过拟合。猜想的原因是本比赛中不需要那么强大复杂的特征提取器,所以将ResNet50进一步减小后再进行特征提取。
将前面的特征层拼接到后面(不只是ResNet的输出,也包括ResNet中的部分特征图),有利于保留原图的细节。
使用不同大小的输入图片,将得到的结果进行融合(Boosting,按照总损失计算不同模型的权重)。
由于将训练数据进行左右翻转、上下翻转、90度、180度、270度旋转等,得到一张图片的多种形式,然后对多种结果进行融合。
End-to-End的全卷积网络 - 代码及训练
项目使用TensorFlow编写,主要参考我之前写好的Semantic-Segmentation-PSPNet项目。
比赛结果
初赛第九名,复赛第十九名,没有进决赛。
模型融合
方法一
对结果进行分析,GoogLeNet对水和道路的效果比较好且边界准确,PSPNet对建筑和植被分的比较好。所以对这两个结果进行融合,将GoogLeNet分类出的水和道路直接覆盖PSPNet分类的结果。
方法二
先用二分类把水分出来:将数据分为两类,即水作为一类,其余的作为另一类。为了使边界准确,使用“按Patch滑窗的卷积网络”进行分类。
然后对剩余的三类使用“End-to-End的全卷积网络”进行像素级分类。
条件随机场和后处理
条件随机场CRF
2015年至2017年,基于深度学习的图像语义分割经常用“条件随机场”作为后处理来对语义分割结果进行优化。
一般来讲,CRF将图像中的每个像素点所属的类别都看作一个变量x_i∈{y1, y2, …, y_c},然后考虑任意两个变量之间的关系。
对CRF能量函数进行优化求解,然后对图像语义分割的预测结果进行优化,得到最终的语义分割结果。
目前,已有将“FCN+CRF”的过程整合到一个端到端的系统中,这样做的好处是CRF的能量函数可以直接用来指导模型参数的训练,从而取得更好的语义分割结果。
去除噪声和孔洞
从预测的结果可以看出,存在大量的小连通区域(小噪声或小孔洞),因此可以通过形态学的方法,把这些去除小连通区域去除替换为周围的类别。
